
pabloriera.github.io/saia
Modelado en
Música y Sonido
.
↓ Scroll o usa las teclas ← → para navegar
Modelado Generativo Parte 1 / 2
Modelos que aprenden a producir audio o secuencias musicales nuevas.
VAE y Modelos de Flujo
Modelos con espacio latente continuo que permiten interpolación e manipulación de atributos.
Qué es
Modelos que aprenden un espacio latente continuo y estructurado. Los VAE codifican audio en distribuciones, permitiendo interpolación y manipulación. Los Flows usan transformaciones invertibles para generación paralela.
Cómo funciona
- Un encoder comprime el audio en parámetros (μ, σ) de una distribución latente
- Se muestrea z ~ N(μ, σ²) usando el reparameterization trick
- Un decoder reconstruye audio/MIDI desde z
- La loss combina reconstrucción + regularización KL
- En Flows: transformaciones invertibles permiten cálculo exacto de likelihood
- Nota: Normalizing Flows (WaveGlow, FloWaveNet) son exactamente invertibles con likelihood tractable. Flow Matching / Rectified Flows (usados en modelos modernos tipo difusión) entrenan trayectorias de transporte óptimo — más flexibles y escalables, pero sin invertibilidad estricta.
Fortalezas
- Interpolación suave entre estilos y atributos musicales
- Espacio latente interpretable; control sobre generación
- VQ-VAE/RVQ: base de tokenizadores para modelos de lenguaje
Falencias
- Reconstrucciones "borrosas" (VAE vanilla)
- Posterior collapse: el decoder ignora z
Condicionamiento típico
- Clase de instrumento, género, atributos musicales (en el espacio latente)
Qué escuchar en estos ejemplos
- Borrosidad: reconstrucciones difusas vs. el original — pérdida de detalle fino
- Interpolación: ¿las transiciones entre estilos son suaves o hay saltos?
- Pitch: estabilidad en notas sostenidas y reconstrucciones
- Noise floor: ruido agregado en la reconstrucción
Fuentes y referencias
GAN (Generative Adversarial Networks)
Dos redes compiten: un generador crea audio sintético y un discriminador intenta distinguirlo de audio real. El resultado: síntesis de alta calidad perceptual.
Qué es
Un framework adversarial donde un generador transforma ruido en audio, y un discriminador evalúa la autenticidad. Ambas redes mejoran en competencia.
Cómo funciona
- Se muestrea un vector de ruido latente z ~ N(0, I)
- El generador G(z) produce un espectrograma o waveform
- El discriminador D(x) clasifica real vs. generado
- Se optimiza min-max: G minimiza y D maximiza la distinción
- En equilibrio, G produce audio indistinguible del real
Fortalezas
- Generación rápida en paralelo (no secuencial)
- Alta calidad perceptual para vocoders (MelGAN, HiFi-GAN)
Falencias
- Mode collapse: poca variedad en las muestras generadas
- Entrenamiento inestable, sensible a hiperparámetros
Condicionamiento típico
- Mel-espectrograma (vocoders: MelGAN, HiFi-GAN), pitch/clase (GANSynth)
Qué escuchar en estos ejemplos
- Metalicidad: “crackle” o brillo artificial en frecuencias altas
- Micro-timing: consistencia del groove y naturalidad rítmica
- Artefactos: clicks, pops o discontinuidades en la forma de onda
- Diversidad: ¿las muestras son variadas o repetitivas? (mode collapse)
Fuentes y referencias
Síntesis Neural / DDSP
Combina modelos físicos de síntesis (osciladores, filtros, ruido) con redes neuronales. Control explícito sobre pitch, loudness y timbre con calidad de audio excepcional.
Qué es
Un paradigma que integra componentes clásicos de síntesis de audio (osciladores armónicos, ruido filtrado, reverberación) como operaciones diferenciables dentro de una red neuronal.
Cómo funciona
- Se analiza el audio de entrada: pitch (f₀), loudness, y opcionalmente timbre
- Una red neuronal predice parámetros de síntesis a partir de estas features
- Componentes diferenciables generan audio: oscilador harmónico + ruido + filtro
- La loss se calcula sobre espectrogramas multi-escala (spectral loss)
- El modelo aprende a reconstruir/transferir timbres con control explícito
Fortalezas
- Control explícito sobre pitch, timbre y dinámica — interpretable
- Transferencia de timbre en tiempo real (Tone Transfer)
- Mucho más eficiente que modelos puramente neurales
Falencias
- Limitado a sonidos quasi-harmónicos (no percusión compleja)
- Requiere buen tracking de pitch como entrada
Condicionamiento típico
- f₀ (pitch), loudness, z_timbre — control explícito sobre síntesis
Qué escuchar en estos ejemplos
- Transferencia tímbrica: ¿suena como el instrumento target o queda híbrido?
- Pitch tracking: estabilidad en notas rápidas, ornamentos y vibratos
- Transientes: calidad de ataques percusivos y consonantes (punto débil)
- Balance harmónico/ruido: proporçción entre componente tonal y breathiness
Autoregresivo / Token-Based
Genera audio o notas token a token, prediciendo el siguiente elemento dado el contexto previo — como un modelo de lenguaje, pero para música.
Qué es
Un modelo que genera secuencias de forma secuencial, prediciendo cada elemento basándose en todos los anteriores. Hay dos regímenes principales:
- AR en waveform (sample-level): genera muestra a muestra directamente (WaveNet, SampleRNN). Máxima fidelidad, extremadamente lento.
- AR sobre códigos discretos (codec tokens): genera tokens de VQ-VAE/RVQ (AudioLM, MusicGen, Jukebox). Opera en espacio comprimido, mucho más rápido y escalable.
Cómo funciona
- El audio se tokeniza (MIDI, VQ-VAE codes, espectro discretizado)
- Un modelo (RNN, Transformer) aprende P(tₙ | t₁…tₙ₋₁)
- En generación, se muestrea token a token
- Los tokens se decodifican a audio (synthesizer, vocoder)
- El contexto crece con cada paso → memoria limitada
Fortalezas
- Excelente coherencia local y continuidad melódica
- Escala bien con datos; base de los LLM musicales modernos
Falencias
- Repetición o "wandering" en piezas largas
- Generación lenta (secuencial por naturaleza)
Condicionamiento típico
- Texto (MusicGen, MusicLM), melodía/audio (priming), género/artista (Jukebox)
Qué escuchar en estos ejemplos
- Coherencia temporal: ¿la pieza mantiene estructura y dirección a largo plazo?
- Repetición: ¿hay loops obsesivos o “wandering” sin rumbo?
- Artefactos de tokens: cuantización audible en modelos de códigos discretos
- Transiciones: naturalidad de los cambios de sección y dinámica
Difusión
Aprende a transformar ruido puro en audio limpio a través de un proceso iterativo de de-noising. El paradigma dominante actual para generación de alta calidad.
Qué es
Un modelo que aprende a revertir un proceso de corrupción gradual con ruido. En generación, parte de ruido puro y lo refina paso a paso hasta obtener audio coherente.
Cómo funciona
- Forward: se agrega ruido gaussiano gradualmente al audio real (T pasos)
- Se entrena una red (U-Net, DiT) para predecir el ruido en cada paso
- Reverse: partiendo de ruido puro, se aplica denoising iterativo
- Opcionalmente se condiciona con texto, clase o audio (classifier-free guidance)
- Waveform diffusion (DiffWave, WaveGrad): opera directamente sobre audio crudo — alta fidelidad, alto costo. Latent diffusion (AudioLDM2, Stable Audio): opera en espacio comprimido (VAE/codec latent), lo que reduce costo computacional y permite mayor duración.
Fortalezas
- Alta calidad y diversidad; no sufre mode collapse
- Condicionamiento flexible (texto, imagen, audio)
Falencias
- Generación lenta (muchos pasos de denoising)
- Límites en duración/coherencia temporal larga
Condicionamiento típico
- Texto (AudioLDM2, Stable Audio), audio/melodía (in-painting), clase/tempo/acorde (Mustango)
Qué escuchar en estos ejemplos
- Calidad tímbrica: naturalidad general — ¿suena “real” o sintético?
- Estructura: ¿hay forma musical (intro, desarrollo, cierre) o es estático?
- Warbling: inestabilidades de frecuencia o “burbujas” en tonos sostenidos
- Noise floor: residuos del proceso de denoising en pasajes suaves
Tokenizers (Audio Codecs como Discretizadores)
Codecs neurales que comprimen audio en tokens discretos. Son el puente entre audio continuo y modelos de lenguaje: la capa fundamental de la generación moderna.
Qué es
Codecs neurales de audio (EnCodec, SoundStream, DAC) que comprimen audio en secuencias de tokens discretos usando Residual Vector Quantization (RVQ). Son la capa de discretización que permite que modelos de lenguaje operen sobre audio.
Cómo funciona
- Un encoder convolucional comprime el audio a baja tasa temporal (~50-75 Hz)
- RVQ cuantiza la representación: Q₁ captura la estructura gruesa, Q₂ el residuo de Q₁, etc.
- Cada nivel de cuantización usa un codebook de ~1024 entradas
- Los IDs del codebook son los "tokens" de audio (típicamente 4–32 niveles RVQ)
- Un decoder reconstruye audio desde los tokens cuantizados
Qué se preserva vs. qué se pierde
- Se preserva: pitch, timbre general, estructura armónica, envolvente dinámica
- Se pierde: fase exacta, micro-timing fino, detalles de ruido, stereo imaging (parcial)
- A mayor bitrate (más niveles RVQ), menor la pérdida perceptual
Por qué importan
- Permiten que modelos AR (AudioLM, MusicGen) generen audio como si fuera "texto"
- Son la base del espacio latente para difusión latente (AudioLDM, Stable Audio)
- Definen el cuello de botella: la calidad del codec limita la calidad final
Modelos clave
- SoundStream (Google, 2021): primer codec neural con RVQ end-to-end
- EnCodec (Meta, 2022): codec de alta calidad, usado en AudioLM y MusicGen
- DAC (Descript, 2023): mejora en calidad musical y menor bitrate
Qué escuchar en reconstrucciones codec
- Cuantización: "burbujeo" o pérdida de definición en transientes rápidos
- Estabilidad tonal: ¿las notas sostenidas mantienen su timbre sin fluctuaciones?
- Imagen estéreo: reducción del campo estéreo respecto al original
- Noise floor: cambios en el ruido de fondo o silencios
Modelado Discriminativo Parte 2 / 2
Modelos que aprenden a analizar, clasificar y representar audio musical. No generan nuevo audio, sino que extraen estructura y significado.
Supervisado (Datos con Etiquetas)
Modelos entrenados con etiquetas humanas para clasificar, etiquetar y detectar eventos en audio. Piedra angular de la clasificación de sonido a gran escala.
Qué es
Modelos entrenados con datasets etiquetados (AudioSet, 2M+ clips) para clasificar eventos sonoros, géneros, instrumentos. Producen embeddings reutilizables como subproducto.
Cómo funciona
- El audio se convierte a mel-espectrograma (ventanas de ~1s)
- Una CNN (MobileNet, VGG16) procesa cada ventana
- Una capa final predice probabilidades sobre 521+ clases de audio
- Se entrena con cross-entropy sobre etiquetas de AudioSet
- Las activaciones intermedias sirven como embeddings transferibles
Fortalezas
- Clasificación robusta de eventos sonoros a gran escala
- Embeddings pre-entrenados reutilizables para downstream tasks
Falencias
- Requiere grandes datasets etiquetados (costoso)
- Sesgo del dataset: sub-representación de géneros/culturas
- No captura relaciones temporales largas
Auto Supervisado (Masking, Asociativo, Contrastivo)
Aprende representaciones de audio sin etiquetas humanas: predicción de parches ocultos, teachers acústicos/musicales, y contrastivo intra-modal.
Qué es
Modelos que aprenden representaciones de audio sin etiquetas humanas, usando señales de supervisión derivadas de los propios datos: parches ocultos, features acústicas/musicales como teachers, y augmentaciones contrastivas.
Paradigmas de SSL
- Masked prediction: se ocultan patches del espectrograma y el modelo los reconstruye. Aprende contexto y estructura (SSAST, EncodecMAE)
- Teacher–Student multi-tarea: un teacher provee targets acústicos y musicales. Los targets concretos incluyen: CQT (espectro armónico), chromagram (perfil de pitch), MFCC (envolvente tímbrica), onset strength (ataques rítmicos), y codebook IDs de HuBERT/Encodec. El student aprende a predecirlos simultáneamente, obteniendo representaciones multi-nivel (MERT, MuQ, MusicFM)
- Contrastivo intra-modal: augmentaciones del mismo audio se acercan; audios diferentes se alejan. Aprende invarianzas útiles (SoniDo)
Fortalezas
- No requiere etiquetas manuales — escala con datos no curados
- Representaciones transferibles a múltiples tareas downstream
- Captura estructura jerárquica: acústica (capas tempranas) → semántica (capas tardías)
Falencias
- Sensible a augmentaciones y selección de teacher
- Puede aprender atajos (shortcuts) en vez de semántica real
- Masked models dependen de la granularidad del tokenizer
Modelado Multimodal
Alinea audio con texto u otras modalidades en un espacio compartido, permitiendo búsqueda cross-modal y zero-shot classification.
Qué es
Modelos que alinean representaciones de audio con otras modalidades (texto, imagen) en un espacio de embeddings compartido. Permiten búsqueda cross-modal y clasificación zero-shot.
Cómo funciona
- Un encoder de audio y un encoder de texto procesan sus inputs en paralelo
- Ambos producen embeddings en el mismo espacio de dimensión fija
- Se entrena con loss contrastiva: pares (audio, texto) correctos se acercan
- Pares incorrectos se alejan en el espacio compartido
- En uso: similitud coseno para retrieval, clasificación sin ejemplos previos
Fortalezas
- Zero-shot classification sin necesidad de fine-tuning
- Búsqueda cross-modal: encontrar audio desde texto y vice versa
Falencias
- Dependencia de la calidad de las descripciones textuales
- Sesgo hacia el dominio del dataset de entrenamiento
- Granularidad limitada en la descripción musical
Análisis de Representaciones
¿Cómo se representa la información en un modelo pre-entrenado? ¿Cómo se organiza la información en las distintas capas?
Qué es
Un enfoque analítico: se toman las representaciones intermedias de modelos SSL y se evalúa con sondas simples qué tipo de información musical codifican en cada capa.
Cómo funciona
- Se congela un modelo pre-entrenado (MERT, MuQ, MusicFM)
- Se extraen embeddings capa por capa
- Una sonda lineal simple se entrena para cada tarea (pitch, género, timbre…)
- Se compara rendimiento por capa → mapa de especialización
- Hallazgo clave: acústico → temprano, semántico → tardío
Fortalezas
- Revela estructura interna: guía la selección de capas
- Permite uso eficiente de modelos grandes sin fine-tuning completo
Falencias
- Probes demasiado simples pueden subestimar información codificada
- Resultados dependen del benchmark y dataset utilizado
📐 Método de evaluación
- Modelos: MuQ (Conformer, 12 capas), MusicFM (Transformer, 12 capas)
- Probe: Clasificador lineal sobre embeddings congelados, una capa a la vez
- Tareas: Singer ID, Pitch detection (acústicas) · Genre classification, Structure segmentation (semánticas)
- Métrica: Accuracy (%) — mide cuánta información útil contiene cada representación por capa
- Fuente: arXiv:2505.16306 — curvas aproximadas de las figuras del paper
⚠️ Las tendencias por capa son dependientes de la arquitectura y el pre-entrenamiento específico. No generalizar directamente entre modelos distintos.
Análisis por capas — MuQ
Método: Valores extraídos de la Tabla 1 del paper arXiv:2505.16306. El gráfico por capa es una aproximación derivada de las figuras del paper.
MuQ — Rendimiento por capa
Generación de Espacio Vectorial (Embeddings)
Extrae embeddings de audio con modelos pre-entrenados y los usa para analizar estructura musical: matrices de auto-similitud, recurrencia y detección de secciones.
Qué es
El proceso de generar representaciones vectoriales de audio usando modelos SSL pre-entrenados (como MuQ) y analizar su estructura temporal. Los embeddings capturan información musical que permite descubrir la forma de una pieza.
Pipeline de análisis
- Se descarga o carga un audio (WAV 16kHz mono)
- Se pasa por un modelo pre-entrenado (MuQ) para obtener embeddings por frame
- Se calcula la matriz de auto-similitud coseno entre todos los frames
- Se construye la recurrence matrix (k-NN binarizada, librosa)
- Agglomerative clustering detecta secciones musicales (verso, estribillo, puente…)
- La curva de novedad muestra cambios: picos = transiciones de sección
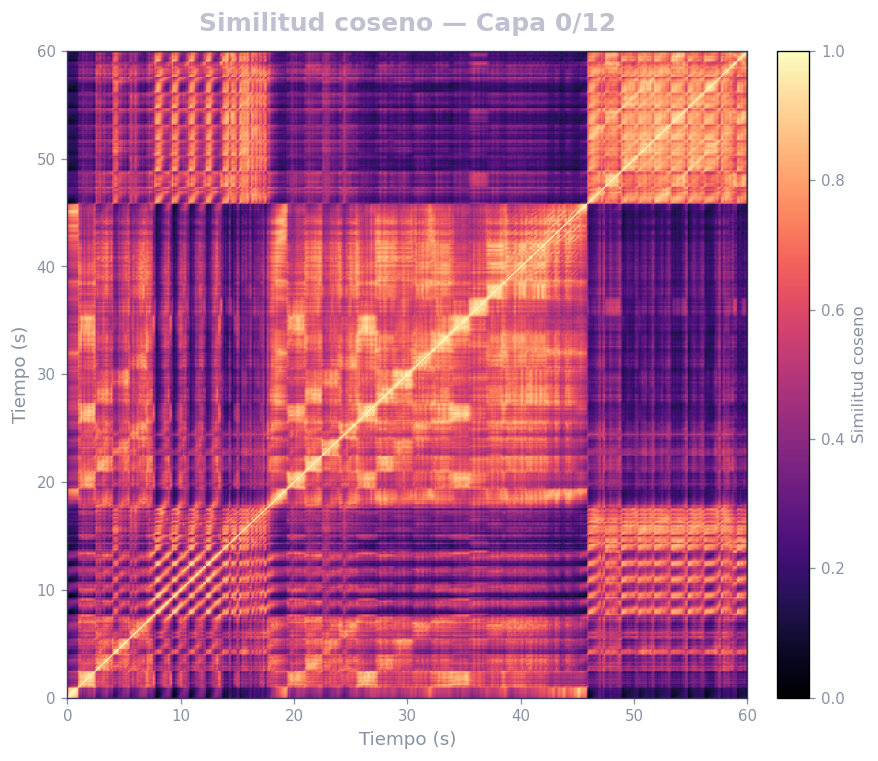
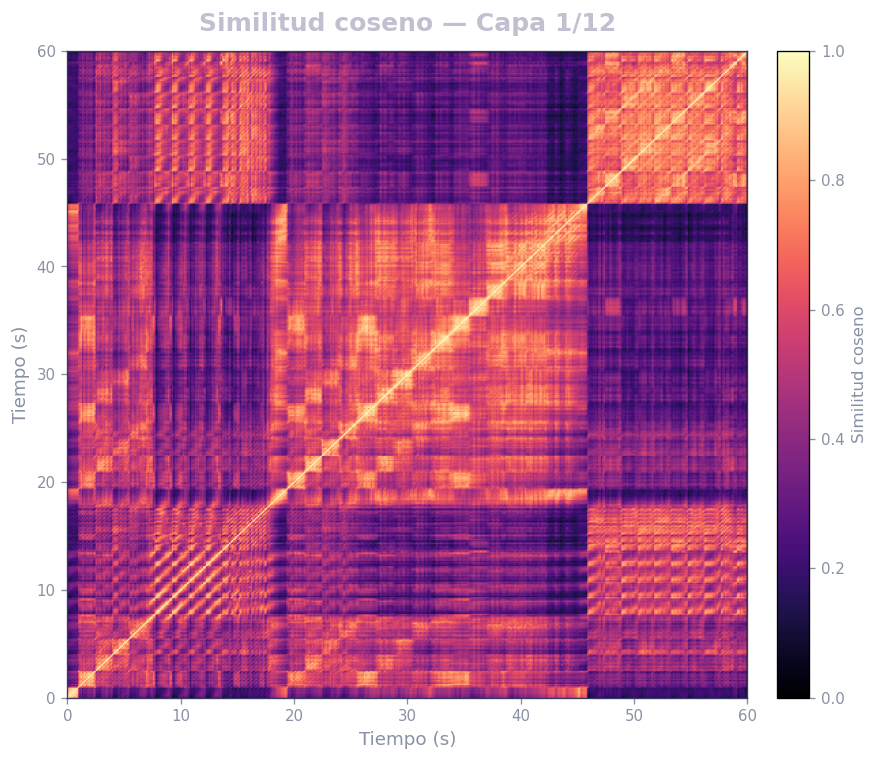
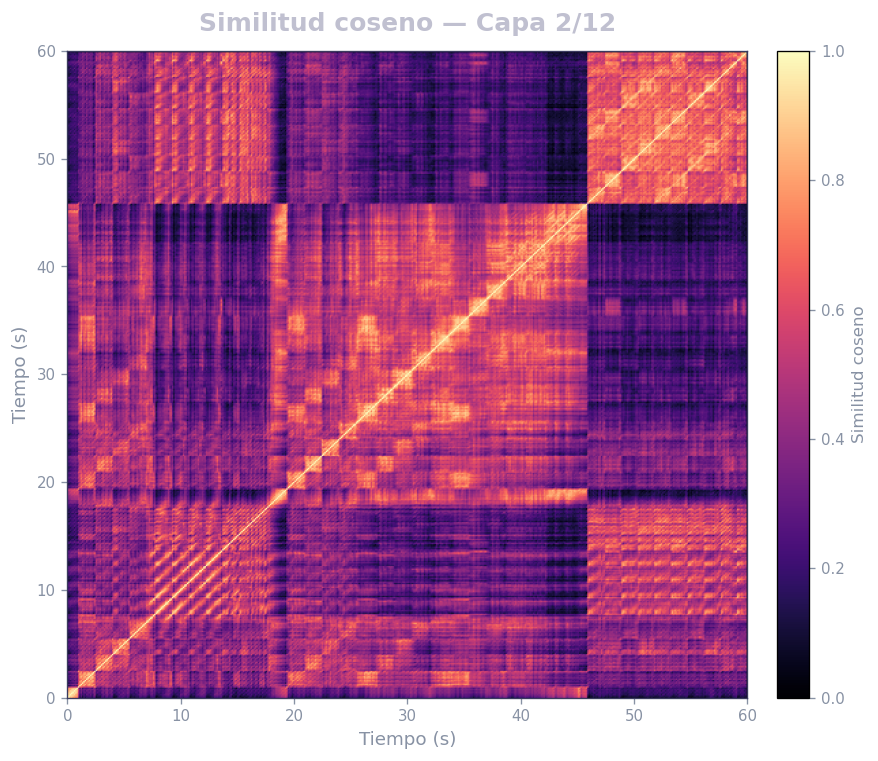
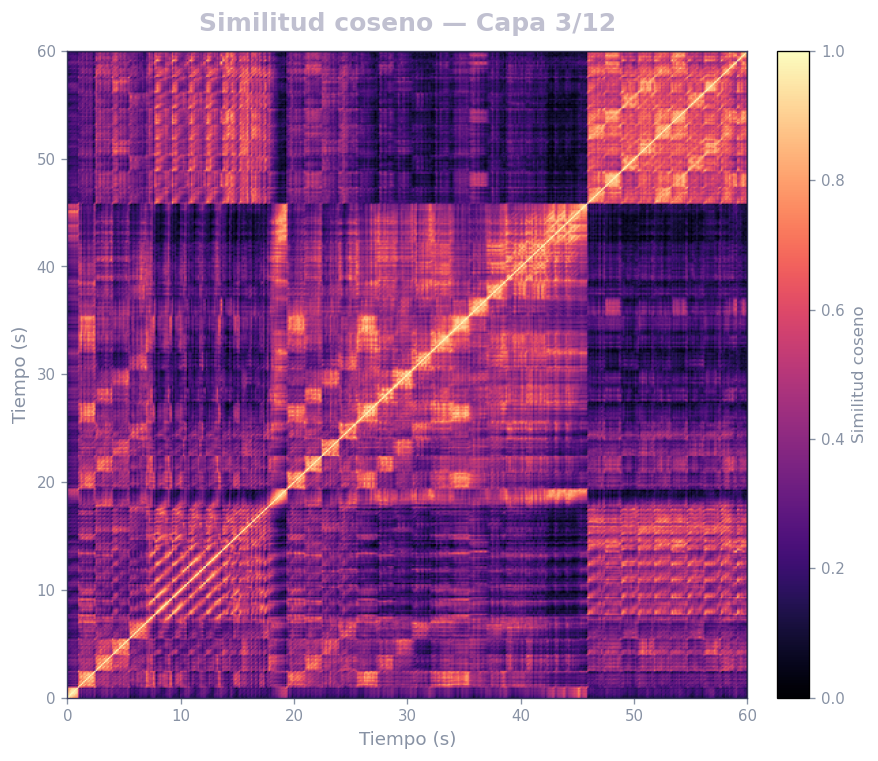
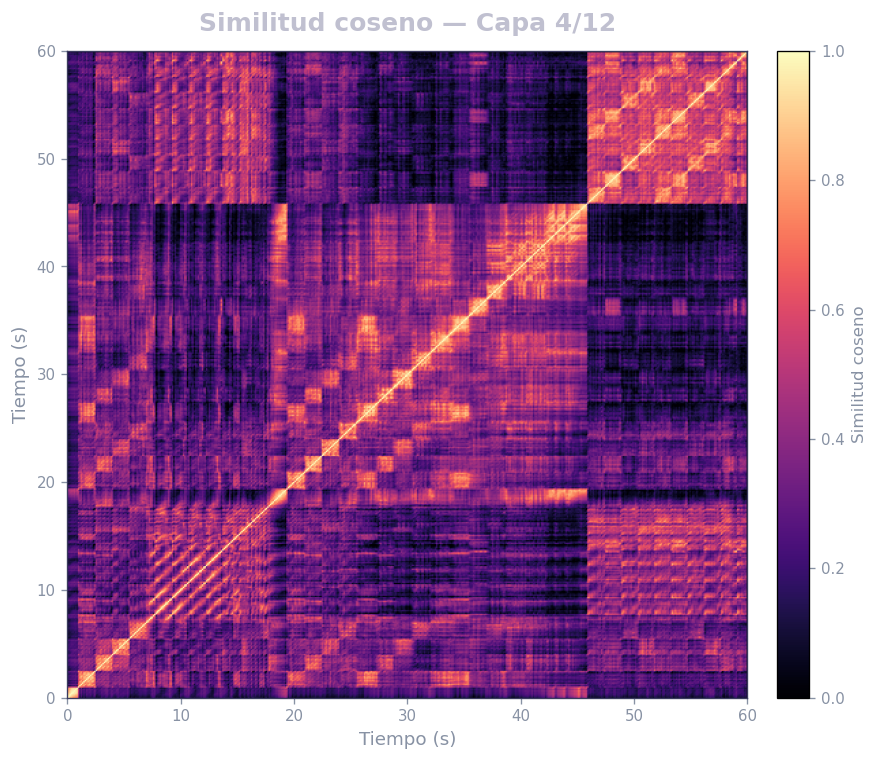
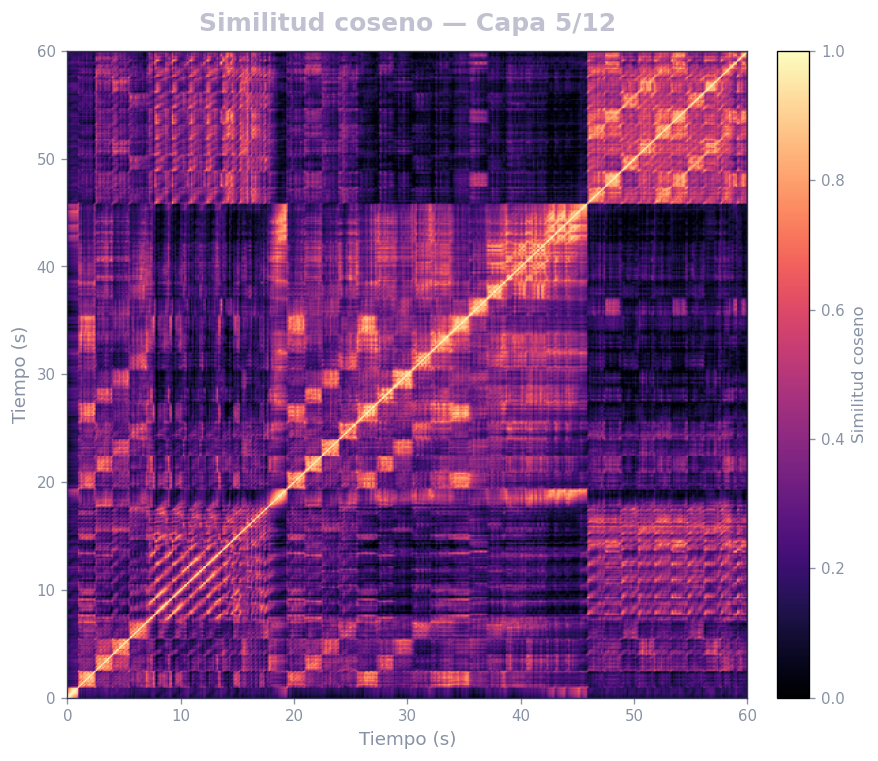
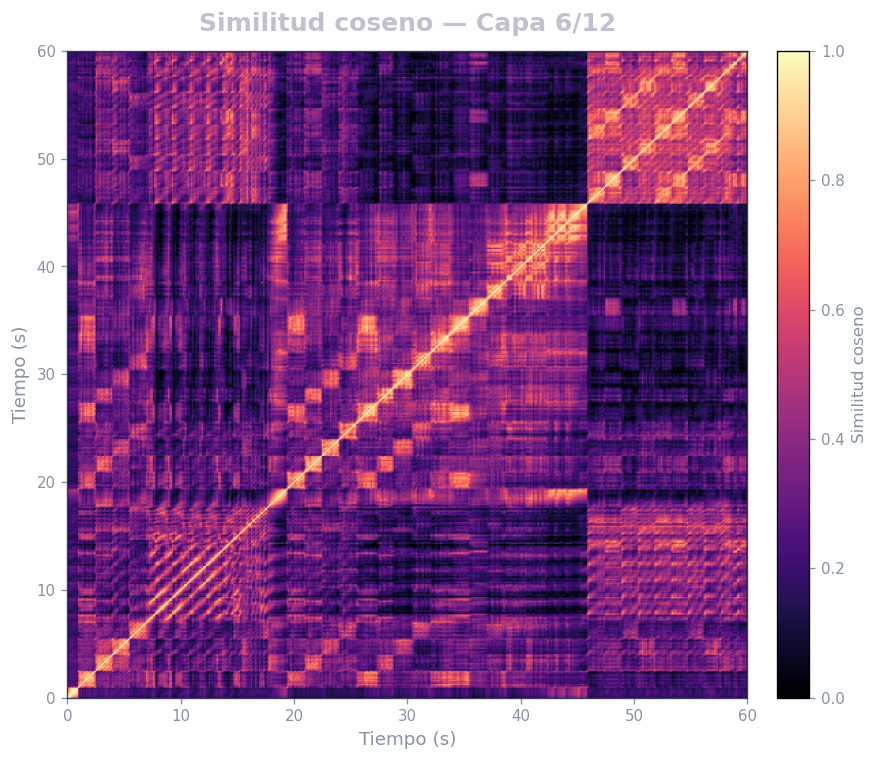
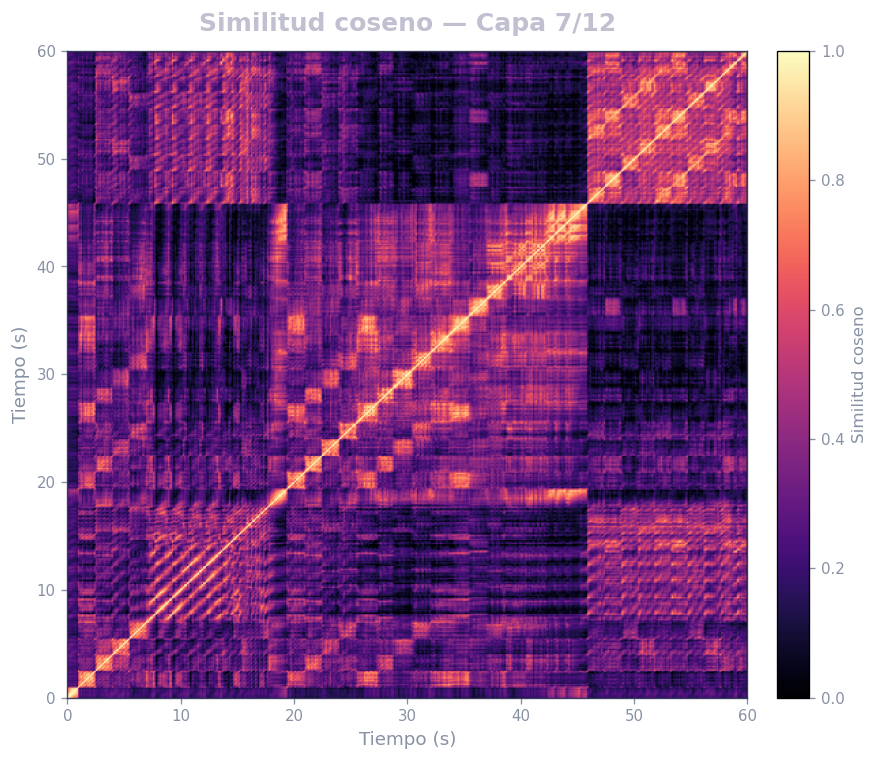
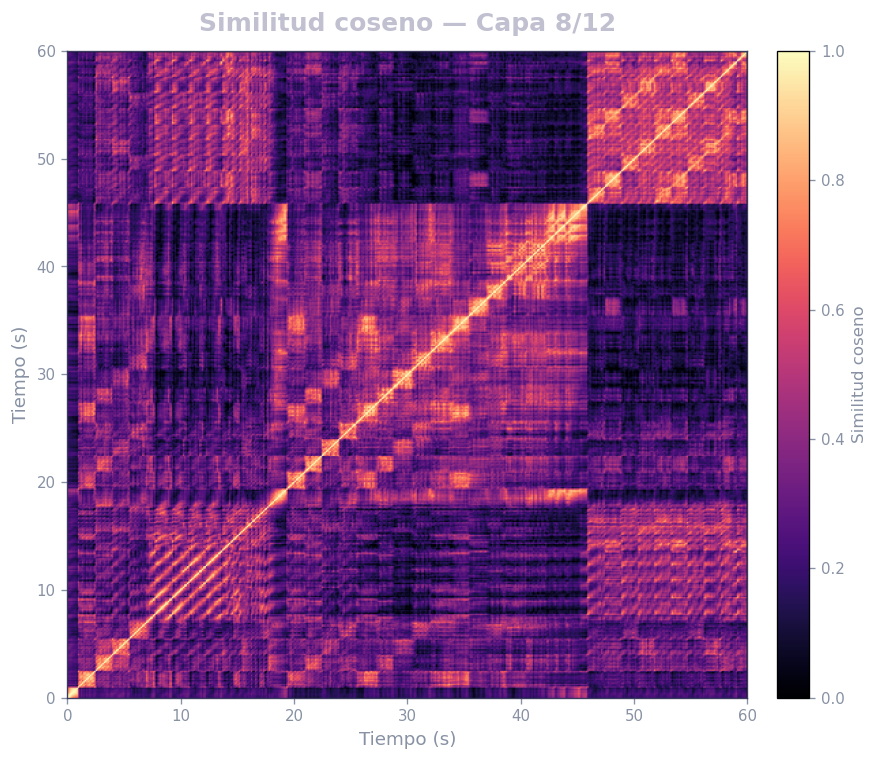
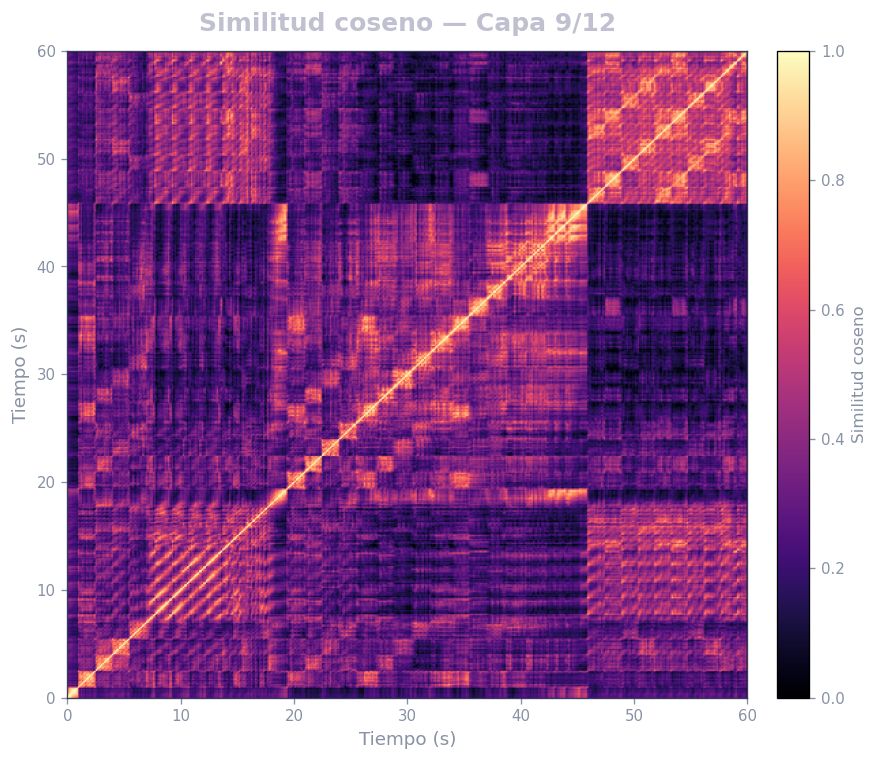
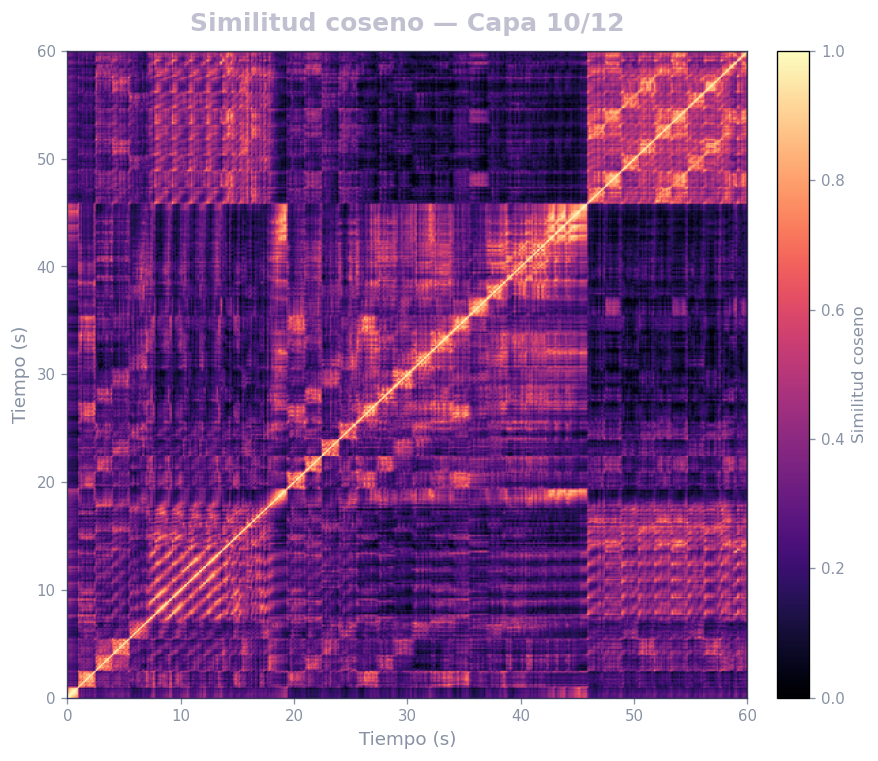
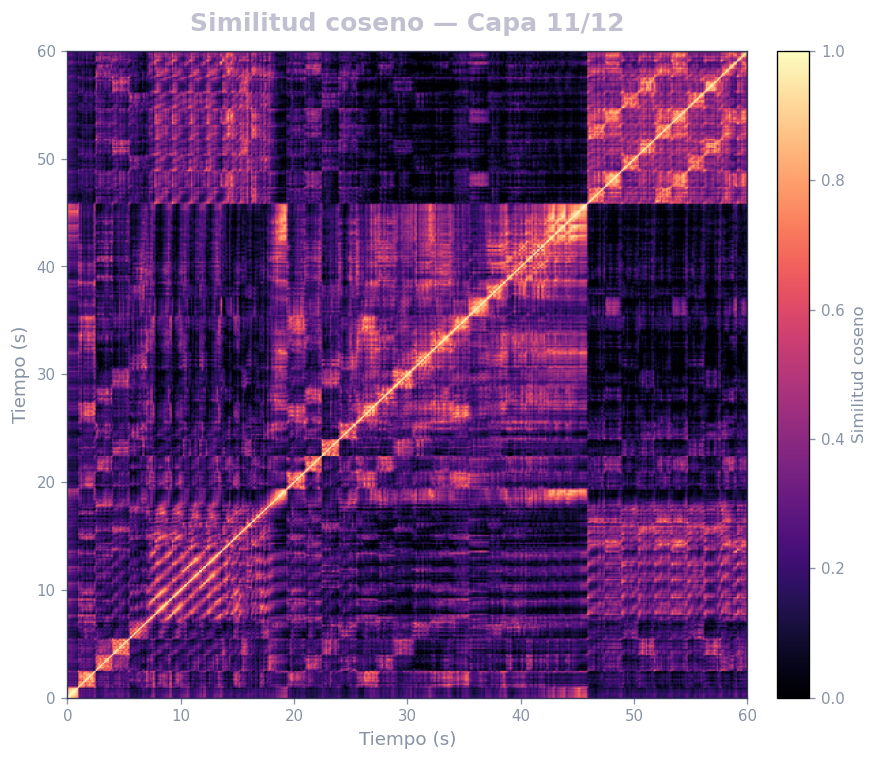
Qué revela
- La diagonal principal = auto-similitud (siempre alta)
- Bloques fuera de la diagonal = secciones que se repiten (forma ABA, AABB…)
- La curva de novedad marca transiciones entre secciones
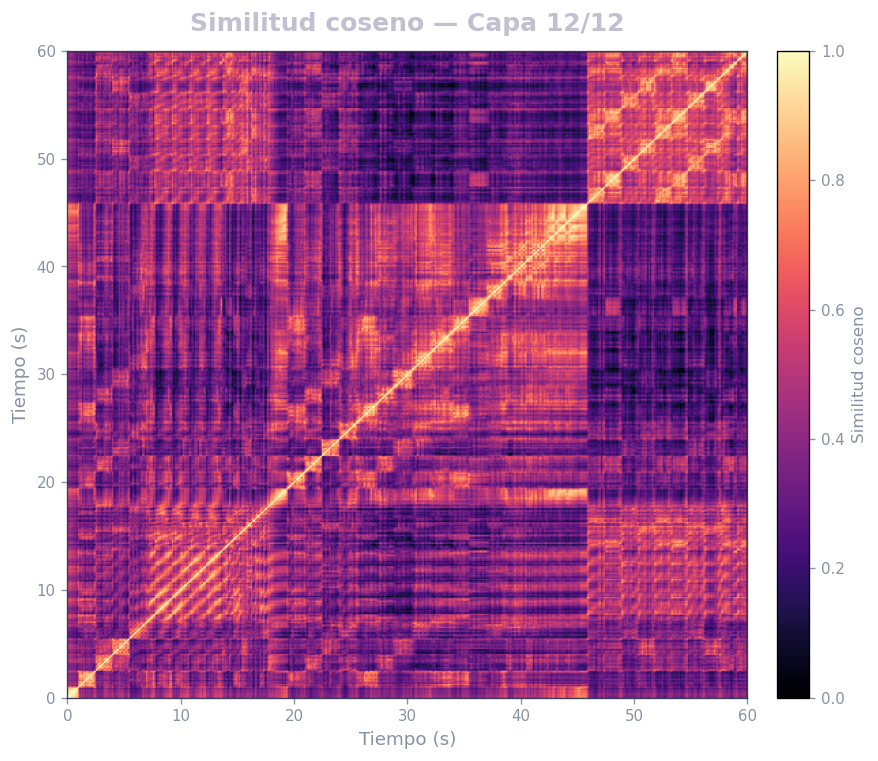
🎹 Matrices de similitud por capa — Mozart K.525 (MERT)
Audio: Mozart — Sinfonía N.º 25 · Modelo: MERT-v1-95M (13 capas) · Cada capa revela distintos niveles de estructura musical.
¡Gracias!
Semióticas, artes e inteligencia artificial — Modelado en Música y Sonido
pabloriera.github.io/saia